Link
Accepted at EMNLP 2021
Intro
信息抽取(Information Extraction, IE)旨在将文本中表达的信息转换为预定义的结构化知识格式。这个总体目标被分解为更容易自动执行和评估的子任务。因此,命名实体识别(Named Entity Recognition, NER)和关系抽取(Relation Extraction, RE)是两个关键的 IE 任务。传统上,这些任务是通过流水线方式执行的。也可以采用联合方式处理,以建模它们的相互依赖性,减少错误传播并获得更现实的评估设置。
随着 NLP 领域的总体趋势,最近在实体和关系抽取基准测试中报告的定量改进至少部分归因于使用了越来越大的预训练语言模型(Language Models, LMs),如 BERT 来获得上下文词表示。同时,人们意识到需要新的评估协议,以更好地理解所获得的神经网络模型的优缺点,而不仅仅是对一个保留测试集上的单一整体指标。
特别是,对未见数据的泛化是评估深度神经网络的关键因素。在涉及提取提及的IE任务中,这一点尤为重要:小范围的词语可能会同时出现在评估和训练数据集中。已证明这种词汇重叠与NER中神经网络的性能相关。对于流水线 RE,神经模型过度依赖候选参数的类型或其上下文中存在的特定触发词。
在端到端关系抽取中,我们可以预期这些 NER 和 RE 会结合在一起。在这项工作中,我们认为当前的评估基准不仅衡量了从文本中提取信息的能力,还衡量了模型在训练期间简单保留标记的(头、谓词、尾)三元组的能力。当模型在训练期间看到的句子上进行评估时,很难区分这两种行为中的哪一种占主导地位。
然而,我们可以假设模型可以简单地检索先前看到的信息,像一个被压缩的知识库一样,通过相关查询进行探测。因此,在包含过多已见三元组的示例上进行测试可能会高估模型的泛化能力。
即使没有标记数据,LMs也能够学习一些单词之间的关系,可以通过填空句子进行探测,其中一个参数被掩盖。
Datasets and Models
数据集选用了 CoNLL04、ACE05、SciERC。
模型选用了三个模型:
- PURE:Pipeline 模型
- SpERT:Joint 模型
- Two are better than one(TABTO):Joint 模型
Partitioning by Lexical Overlap(基于词汇重叠的划分)
我们根据与训练集的词汇重叠情况对测试集中的实体提及进行划分。我们区分了已见和未见的提及,并将这种划分扩展到关系上。
我们实现了一个简单的保留启发式方法(Retention Heuristic,启发式方法),将训练集中确切存在的实体提及或关系标记为其多数标签。我们在表1中报告了 NER 和 RE 的 Micro-avg. 精度、召回率和 F1 分数。
如果一个实体提及的边界和类型都被正确预测,则认为该实体提及是正确的。对于 RE,我们在边界和严格设置中报告分数(。在边界设置中,如果关系的类型正确且其参数的边界正确,则认为关系是正确的,而不考虑其类型的检测。严格设置增加了参数实体类型也必须正确的要求。
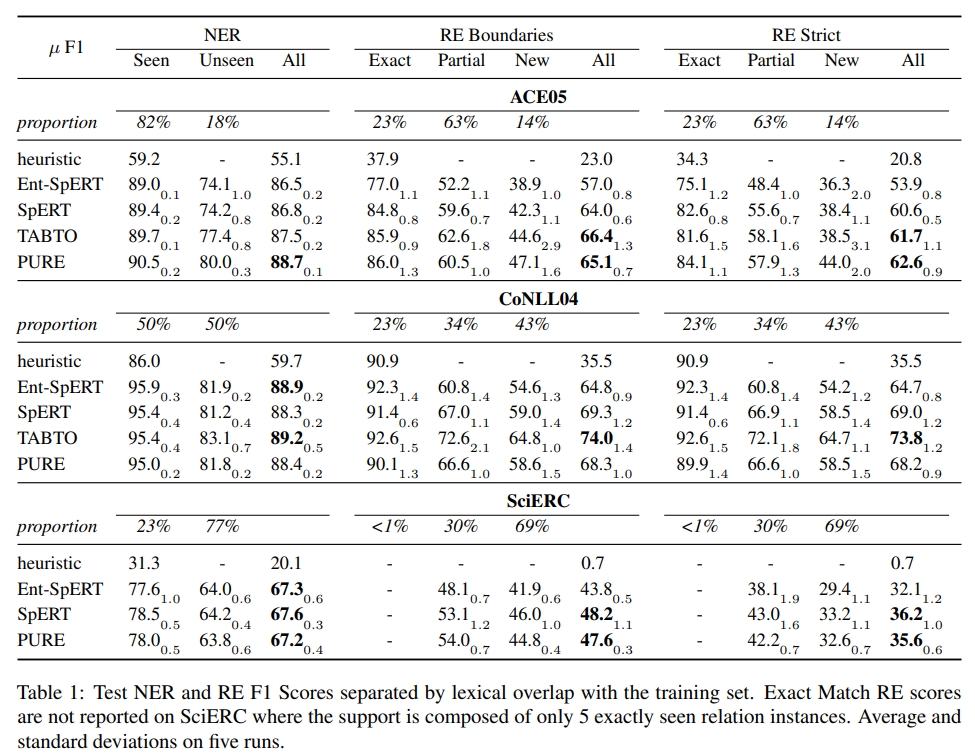
虽然我们无法在 SciERC 数据集上评估 TABTO,因为它不适合提取嵌套实体,但我们可以注意到每个数据集上的模型层次不同,这表明至少在当前的评估设置中,没有一种通用的最佳模型。
最明显的比较是 SpERT 和 Ent-SpERT 之间的比较,其中上下文的显式表示被删除。这导致在关系抽取(RE)部分的性能下降,特别是在部分匹配或新关系上,因为这些实体表示对在训练中未见过。Ent-SpERT 在 CoNLL04 数据集上的精确匹配特别有效,表明其保留能力。
其他比较则更为困难,因为每个模型的结构以及训练过程存在诸多差异。然而,PURE 管道设置似乎仅在 ACE05 上更有效,因为其命名实体识别(NER)性能显著更好,可能是因为学习了单独的 NER 和 RE 编码器,从而能够为每个独特任务学习和捕获更多特定信息。即便如此,TABTO 在边界性能上表现更好,仅在严格设置中因实体类型混淆而受到惩罚。相反,在 CoNLL04 上,TABTO 显著优于其对手,特别是在未见过的关系上。这表明它在这种情况下更有效地结合了上下文信息,其中关系和参数类型是双射映射的。
在 SciERC 上,所有模型的性能在 RE 步骤之前的 NER 级别上已经受到影响,这使得模型性能之间的进一步区分更加困难。
Swapping Relation Heads and Tails
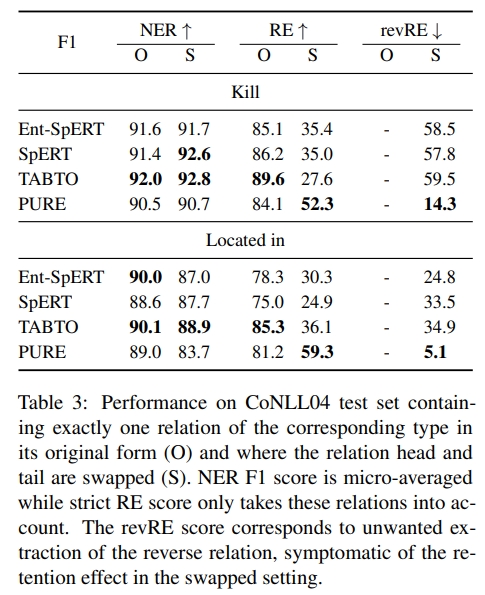
为了验证模型预测中保留作为启发式方法的使用,我们选择在同类型实体之间发生的不对称关系,并在输入中交换头和尾。如果模型预测出原始三元组,那么它过度依赖于保留启发式方法,而找到交换后的三元组则证明了更广泛的上下文整合。我们在表2中展示了一个例子。

由于实验的要求,我们必须限制在 CoNLL04 数据集中两个关系:“Kill”(杀死)在人物之间和“Located in”(位于)在地点之间。实际上,CoNLL04 是唯一一个关系类型和其参数类型之间存在双射映射的数据集,并且一致的专有名词使得交换在语法上大多是正确的。对于每种关系类型,我们只考虑包含一个对应关系实例的句子,并交换其参数。我们只考虑表3中报告的RE分数中的这种关系。我们使用严格的RE分数以及 revRE 分数来衡量句子中未表达的反向关系的提取。
对于每种关系,模型的层次结构与整体 CoNLL04 相对应。交换参数对 NER 的影响有限,主要是对“Located in”关系。然而,这导致每个模型的 RE 下降,并且 revRE 分数表明 SpERT 和 TABTO 更频繁地预测反向关系,而不是新表达的关系。这是端到端模型保留启发式方法的另一个证明,尽管这也可能归因于语言模型。特别是对于“Located in”关系,交换后的头和尾并不完全等价,因为前者主要是城市,后者是国家。
相反,PURE 模型不太容易保留信息,如其 revRE 分数显著小于交换句子的标准 RE 分数所示。因此,它在交换句子上优于 SpERT 和 TABTO,尽管在原始数据集上效果最差。结果的重要差异可以通过这些模型使用的不同类型的表示来解释。流水线方法允许在关系分类器中使用参数类型表示,而大多数端到端模型使用共享的实体表示中的词汇特征用于 NER 和 RE。