
Link
Accepted EMNLP 2023.
EMNLP:CCF B
Related Works
这一部分内容本来是在论文的最后面,但是考虑到这篇论文也算是打开了新世界的大门,所以把这个放在最前面。
关系抽取(Relation Extraction,RE)大致可以分为三种:
语句级 RE(Sentence-Level RE):早期的研究主要集中在预测单个句子内两个实体之间的关系。各种基于模式和神经网络的方法在句子级关系抽取上取得了令人满意的结果。然而,句子级关系抽取在抽取范围和规模上有显著的局限性。
可以说是早期的 RE 大多是这一类别。
文档级 RE (Document-Level RE,DocRE):现有的大多数文档级关系抽取研究都基于数据驱动的监督场景,通常分为基于图和基于序列的方法。基于图的方法通常通过图结构抽象文档,并使用图神经网络进行推理。基于序列的方法则使用仅包含变压器的架构来编码长距离的上下文依赖关系。这两类方法在文档级关系抽取中都取得了令人印象深刻的结果。然而,这些方法对大规模标注文档的依赖使得它们难以适应低资源场景。
小样本文档级 RE (Few-Shot Document-Level RE,FSDLRE):为了应对现实世界文档级关系抽取场景中普遍存在的数据稀缺问题,Popovic等将文档级关系抽取任务形式化为小样本学习任务。为了完成这一任务,他们提出了多种基于度量的模型,这些模型建立在最先进的监督文档级关系抽取方法和少样本句子级关系抽取方法的基础上,旨在解决不同任务设置的问题。有效的基于度量的少样本文档级关系抽取方法的每个类别的原型应该准确捕捉相应的关系语义。然而,由于现有方法的粗粒度关系原型学习策略和”一刀切”的 NOTA 原型学习策略,这对现有方法来说是一个挑战。
术语解释:
原型学习(Prototype-Based Learning)是一种通过存储一组代表性样本(原型)来进行分类、回归或聚类的学习方法。原型学习的主要步骤包括:
- 选择原型:从训练数据中选择一组代表性的样本作为原型。
- 计算距离:使用距离度量(如欧氏距离、曼哈顿距离等)来确定测试样本与原型之间的相似性。
- 分类或聚类:将测试样本分配给最接近的原型,从而确定其所属的类别或簇。
NOTA Prototype 在本文中指的是 “None-Of-The-Above” 原型,用于处理那些不属于任何目标关系类型的实体对。以下是其主要特点:
任务特定:每个任务生成特定的 NOTA 原型,以更好地捕捉该任务中的 NOTA 语义。
基础原型:引入一组可学习的基础 NOTA 原型,这些原型需要在每个任务中进一步修正。
支持实例选择:从支持文档中选择 NOTA 实例,并将其与基础NOTA原型融合,生成最终的任务特定NOTA 原型。
语义捕捉:通过这种方法,NOTA 原型不仅包含了元学习的通用知识,还能捕捉每个任务中的特定NOTA 语义。
Intro
FSDLRE 任务的简单描述:
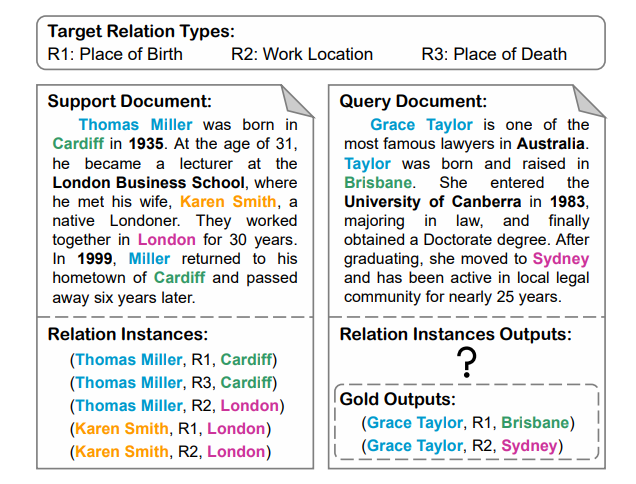
Illustration of a 1-Doc FSDLRE task. Entity mentions involved in relation instances are colored and in bold. Other mentions are also in bold for clarity.
基于度量的元学习(Metric-Based Meta Learning)是广泛采用的 FSDLRE 有效框架,它通过构建类原型进行分类。然而,现有工作在获取具有准确关系语义的类原型时往往存在困难:
- 为了构建目标关系类型的原型,它们聚合了所有持有该关系的实体对的表示,而这些实体对可能还持有其他关系,从而干扰了原型。
- 它们在所有任务中使用一组通用的NOTA(none-of-the-above)原型,忽略了在具有不同目标关系类型的任务中,NOTA语义是不同的。
基于以上两点,本文提出了关系感知原型学习方法(Relation-Aware Prototype Learning,RAPL)。首先,对于支持文档中持有关系的每对实体,我们利用关系描述中的内在关系语义作为指导,推导出每个表达关系的实例级表示,如下图所示。通过聚合所有支持关系实例的表示来构建关系原型,从而更好地聚焦于与关系相关的信息。
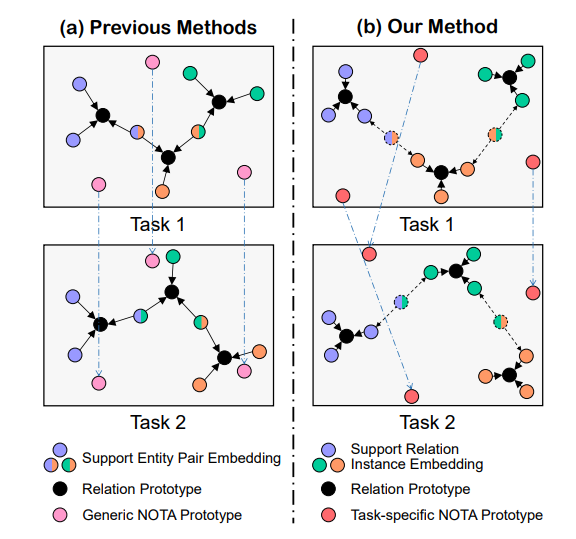
Embedding space illustration of previous methods (left) and our method (right). Task 1&2 are two FSDLRE tasks with different target relation types.
Problem Formulation
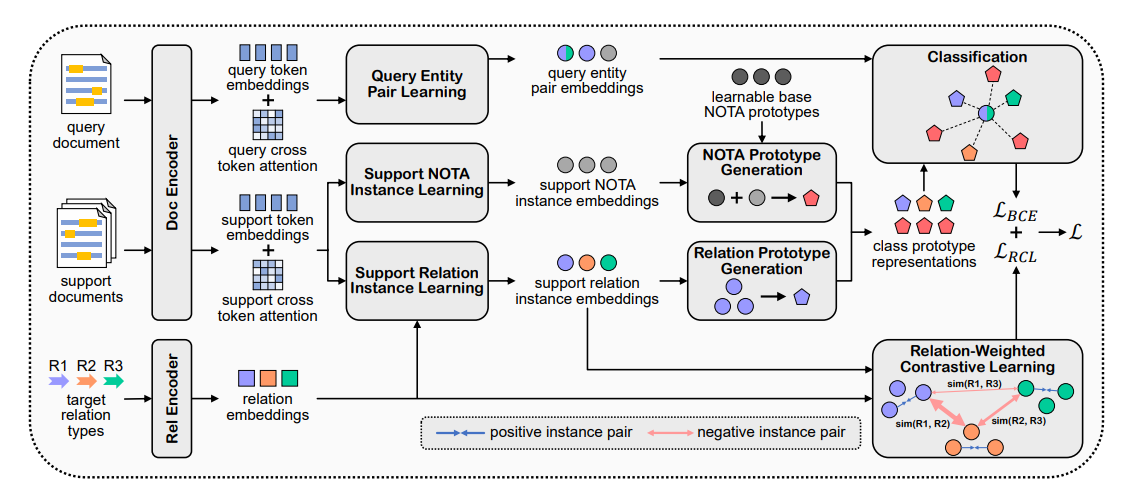
The overall architecture of our proposed RAPL method.
Methodology
Document and Entity Encoding
我们使用预训练语言模型作为文档编码器来编码给定任务中的每个支持或查询文档。对于每个文档,我们首先在每个实体提及的开始和结束位置插入一个特殊标记 “*” 以标记实体提及的位置。然后我们将文档输入编码器以获得上下文的 token embedding 和 cross-token attention 。我们将到每个实体前的“*”标记为止的文本作为 mention embedding 。对于文档中提及的实体,我们通过对 mention embedding 进行log-sumexp 池化来获得 entity embedding 。
Relation-Aware Relation Prototype Learning
对于给定任务中的每个目标关系类型,我们旨在获得一个能够更好地捕捉相应关系语义的原型表示。为此,我们首先提出基于实例级支持嵌入来构建关系原型,使每个原型能够更专注于支持文档中的关系相关信息。然后,我们提出一种实例级关系加权对比学习方法,进一步优化关系原型。
Instance-Based Prototype Construction
对于支持文档中的关系实例,我们首先计算文档中所有 token 的 pair-level 重要性分布,以捕捉与实体对相关的上下文。同时,我们计算关系级注意力分布,以捕捉与关系相关的上下文。我们使用另一个预训练语言模型作为关系编码器,将关系的名称和描述连接成一个序列,然后将序列输入编码器。我们将“[CLS]”标记的输出嵌入作为 relation embedding 。
基于 pair-level 和关系级注意力分布,我们进一步计算实例级注意力分布,以捕捉与实例相关的上下文。具体来说,实例级注意力分布的值由 pair-level 和关系级注意力分布的值相加得到。
Contrastive-Based Prototype Refining
之前的方法难以与对比目标整合,因为它们仅获得了对支持集实体对的嵌入。实体对的多标签特性使得合理定义正负对变得困难。此外,通过结合关系间的相似性,提出的对比损失更关注于将语义上接近的关系实例嵌入分开,从而有助于更好地区分相应的关系原型。
Relation-Aware NOTA Prototype Learning
由于大多数查询实体对不持有任何目标关系,NOTA(none-of-the-above)也被视为一个类别。现有方法通常学习一组通用的 NOTA 原型,应用于所有任务,这在某些任务中可能并不理想。为此,我们提出一种任务特定的 NOTA 原型生成策略,以更好地捕捉每个任务中的 NOTA 语义。
具体来说,我们首先引入一组可学习的向量,作为基础 NOTA 原型。与直接将这组向量视为最终 NOTA 原型不同,我们将其视为需要在每个任务中进一步修正的基础 NOTA 原型。由于支持文档的注释是完整的,我们可以访问支持 support-NOTA 分布,这隐含地表达了 NOTA 语义。因此,我们利用 support-NOTA 实例来捕捉每个特定任务中的 NOTA 语义。
Training Objective
给定查询文档中的实体对,我们使用 pair-level 注意力分布并采用类似的方法获得 pair-level 表示。对于任务中的每个目标关系类型,我们计算关系的概率。然后,我们计算分类损失。
Experiments
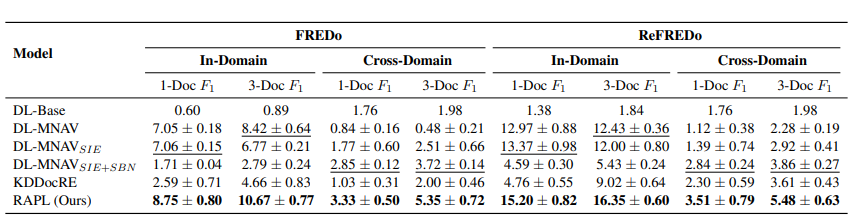
Results on FREDo and ReFREDo benchmarks. Reported results are macro averages across relation types. The best and second best performance methods are denoted in bold and underlined respectively.