Link
[2109.05362] Modular Self-Supervision for Document-Level Relation Extraction (arxiv.org)
Accepted at EMNLP 2021
Intro
信息抽取的先前工作通常集中在句子内的二元关系。然而,实际应用往往需要跨大段文本提取复杂关系。这在生物医学等高价值领域尤为重要,因为获取最新发现的高召回率至关重要。例如,图1显示了一个三元(药物、基因、突变)关系,表明具有 MAP2K1 突变 K57T 的肿瘤对 cobimetinib 敏感,但这些实体从未在同一段落中同时出现。

先前的工作都将文档级关系抽取视为一个单一的整体问题,这在推理和学习上都带来了重大挑战。尽管最近取得了一些进展,但在使用最先进的神经架构(如LSTM 和 transformer)建模长文本范围时仍存在显著挑战。此外,直接监督稀缺,任务特定的自监督(如距离监督)在应用于短文本范围之外时变得极其嘈杂。
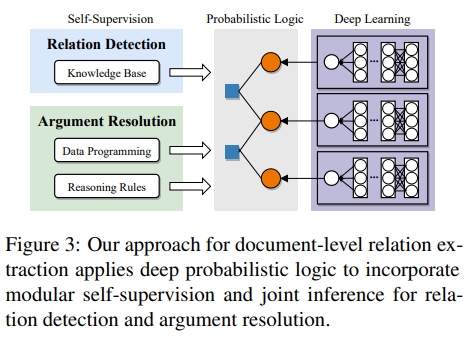
在本文中,我们通过将文档级关系抽取分解为局部关系检测和全局推理来探索一种替代范式。具体来说,我们使用 Davidsonian 语义表示 $n$ 元关系,并结合段落级关系分类和使用全局推理规则(例如,参数解析的传递性)的篇章级参数解析。每个组件问题都存在于短文本范围内,其相应的自监督错误率要低得多。我们的方法借鉴了模块化神经网络和神经逻辑编程的灵感,将复杂任务分解为局部神经学习和全局结构化集成。然而,我们不是从端到端的直接监督中学习,而是承认组件问题的模块化自监督(Modular Self-Supervision),这更容易获得。
这种模块化方法不仅使我们能够处理长文本,还能扩展到所有先前方法无法覆盖的跨段落关系。我们在精准肿瘤学的生物医学机器阅读中进行了全面评估,其中跨段落关系尤为普遍。我们的方法在最具挑战性的关系中表现尤为突出,这些关系的参数从未在段落中同时出现,其F1分数比之前的最先进方法(如多尺度学习(和图神经网络高出20多个百分点。
Document-Level Relation Extraction
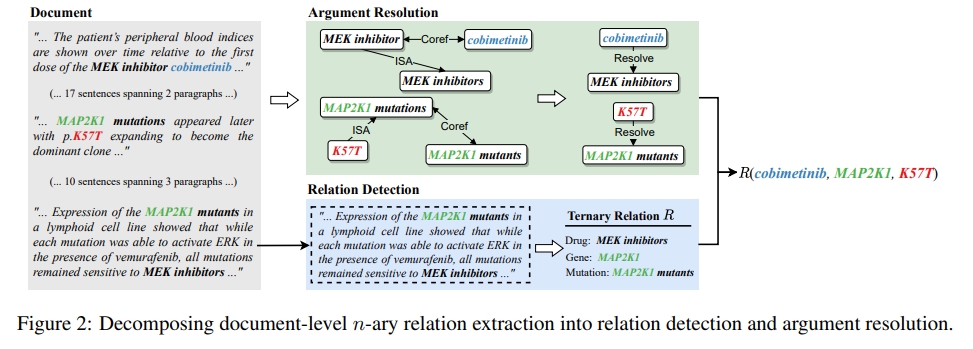
设 $E,R,D$ 分别代表实体、关系、文档,那在图2中的 $R$ 为精准癌症药物反应,实体 $E_1,E_2,E_3$ 分别药物 cobimetinib、基因 MAP2K1 和突变 K57T。这个关系跨越多个段落和几十个句子。
用新戴维森语义表示 n 元关系抽取:
$$ R_D(E_1, \cdots, E_n) \equiv \exists T \in D \exists r. [R_T(r) \land A_1(r, E_1) \land \cdots \land A_n(r, E_n)] $$其中,$T$ 为文档 $D$ 中的片段,$r$ 为引入的事件变量以表示 $R$ 。
这种分布式表示适用于任意 $n$ 元关系,当参数缺失或添加新参数时不需要进行重大更改。根据这种表示,文档级关系抽取自然分解为局部关系检测(例如,分类
$R_T(r)$ 是否对段落 $T$ 成立)和全局参数解析(例如,分类 $A(r,E_1)$)。
剩余数学定理部分略,详见原文。
Modular Self-Supervision
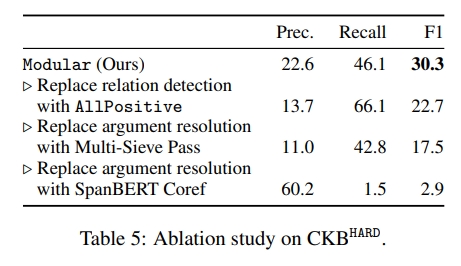
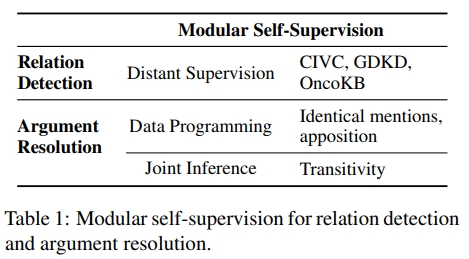
我们的问题公式使得引入模块化自监督用于关系检测和参数解析变得自然(见表1)。
关系检测:目标是训练一个分类器来判断 $R_T(r)$ 。本文中,我们将段落作为 $T$ 的候选,并使用远程监督进行自监督。具体来说,使用包含已知关系实例的知识库(KB)来注释未标记文本中的示例。已知关系的共现提及元组被标注为正例,而那些没有已知关系的则被采样为负例。这些示例用于训练段落级的关系分类器。我们利用段落级远程监督噪声较小的事实,但文档级关系提及仍然遵循与段落级相似的文本模式,如图2所示。
参数解析:目标是基于局部上下文训练一个分类器来判断 $Resolve(e, e0)$ 。为了自监督,我们引入数据编程规则,捕捉相同提及和同位语。这些规则作为种子自监督,用于标注高精度的解析实例。随后,通过应用传递规则,可以在同一文档中生成更多实例。
Our Model
Experiments