Link
Accepted COLING 2024
COLING: CCF B
Intro
关系抽取是自然语言处理领域中的一个基本且重要的任务,旨在从句子或文档中提取实体之间的潜在关系。传统的 RE 方法在大量标注样本上训练模型,然后在具有相同标签空间的数据上进行测试。然而,在现实生活中,新关系不断涌现,这些模型在适应新关系时可能会出现显著的性能下降。此外,这些模型严重依赖于大量标注数据,这需要大量时间和精力来收集。
因此,提出了持续少样本关系抽取(Continual Few-shot Relation Extraction, CFRE),其目标是在有限的标注数据约束下,持续学习新关系的同时保留先前学习的关系知识。这一实际任务带来了两个重大挑战:
- 灾难性遗忘:模型在学习新任务时突然忘记从前任务中获得的知识。最新研究指出,即使在大型语言模型中也存在灾难性遗忘问题,这使得这一问题值得研究。
- 过拟合:模型在训练数据上表现异常好,但由于拟合噪声或无关模式,无法有效泛化到未见数据,这在训练数据稀少的低资源场景中更为明显。
总结一下,我们的主要贡献包括:
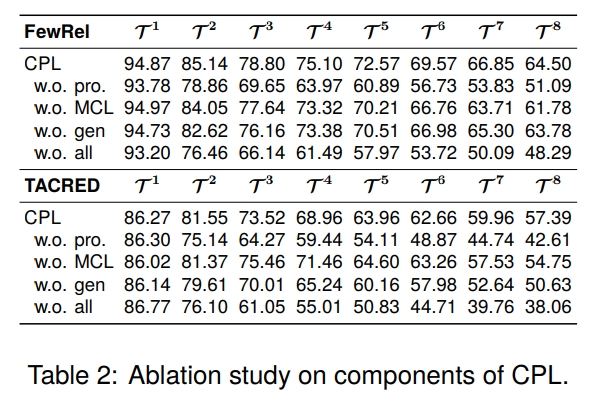
- 我们利用提示学习来探索预训练语言模型(PLM)的隐含能力,并提出了 Contrastive Prompt Learning framework (CPL) 框架,将其与一种新的基于边际的对比学习目标(CFRL)结合起来,同时缓解灾难性遗忘和过拟合问题。
- 我们通过利用大型语言模型(LLM)的力量引入了一种记忆增强策略,以提升较小的 PLM。这种策略使用精心设计的提示来指导 ChatGPT 生成样本,从而更好地对抗过拟合。
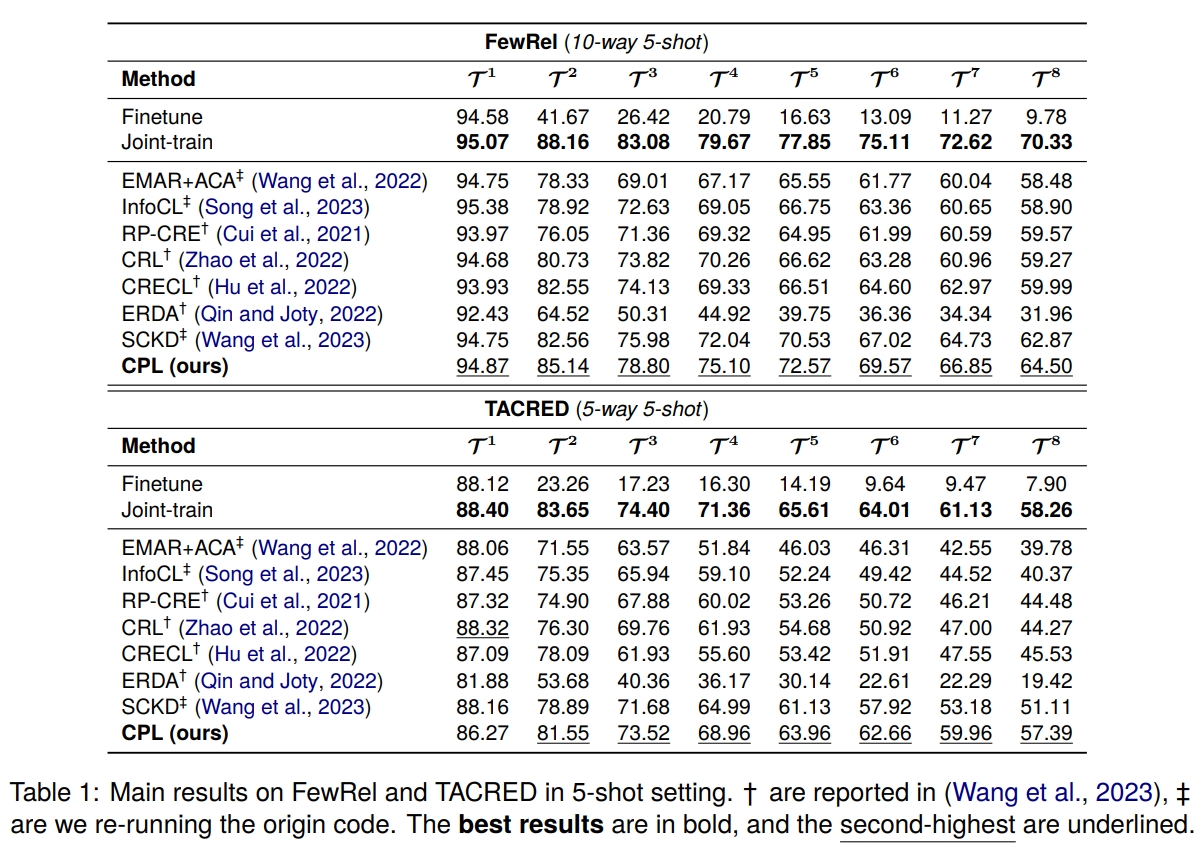
- 在两个 RE 基准上的大量实验表明,我们的方法优于最先进的模型,证明了缓解灾难性遗忘和过拟合的有效性。
Related Work
Continual Learning
持续学习(Continual Learning, CL)旨在从一系列任务中不断学习新知识,同时避免遗忘旧知识。CL的主要挑战是灾难性遗忘。
现有的CL方法分为三类:
- 正则化方法:使用额外的约束来限制参数更新,使模型能够记住更多旧知识。
- 动态架构方法:动态扩展模型架构,以在任务序列不断出现时存储新知识。
- 基于记忆的方法:存储当前任务的一些典型样本,并在学习任务序列后重放记忆以复习旧知识。
在这些方法中,基于记忆的方法在自然语言处理(NLP)任务中最为有效。然而,新任务的数据并不总是充足的,而且获取高质量数据往往既昂贵又耗时。我们也采用基于记忆的策略,但我们更注重如何更好地利用预训练语言模型(PLMs)来解决 CFRE。
Prompt Learning
提示学习随着GPT-3系列的诞生而出现,并在自然语言处理任务中取得了显著的性能,尤其是在小样本场景中。它通过添加提示词将下游任务重新表述为预训练任务,并引导预训练语言模型(PLMs)理解各种任务。之前的提示学习方法可以分为三类:
- 硬提示:在句子中添加手工制作的提示词,并将其转换为掩码语言建模问题。尽管有效,但它需要针对不同任务的复杂专家知识,这既繁琐又耗时。
- 软提示:在句子中添加可连续训练的向量,这些向量可以被模型自动学习。然而,在没有任何先验专家知识的情况下,模型并不总能学到合适的提示,尤其是在低资源场景中。
- 混合提示:结合不可调的硬提示和可调的软提示,使模型能够在少量人工干预下轻松学习合适的模板。它被验证为最有效的方法。
我们专注于少样本设置,并采用混合提示来帮助预训练语言模型(PLMs)缓解灾难性遗忘和过拟合问题。
Method
Framework Overview
整个 CPL 框架有三个模块:
- Prompt Representation,Contrastive Learning,Memory Augmentation
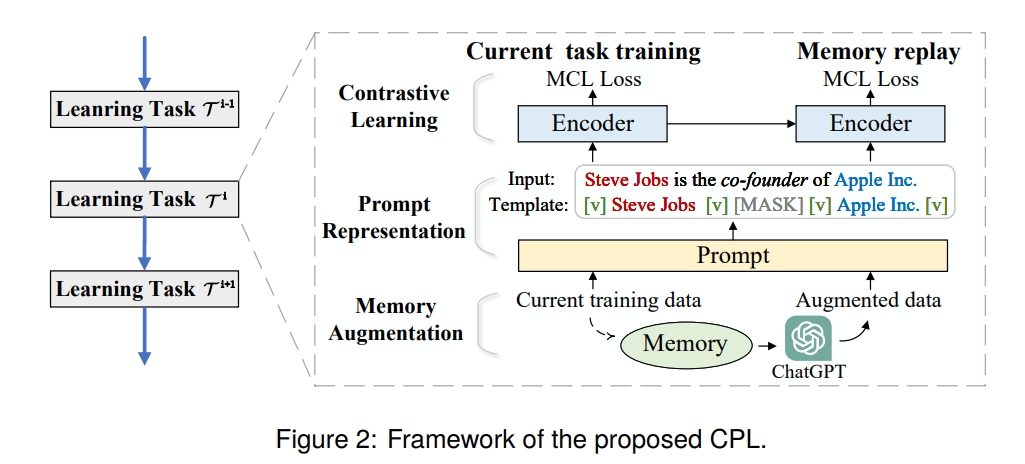
Prompt Representation
我们提出了一种有效的半自动模板用于关系抽取(RE),将RE从分类问题转换为基于上下文的文本填充问题。
给定一个输入 $x = [x_0,...,x_n]$,先将其转换为模板 $T(x)=[x_0,...,[E_0], e_h,[E_1], ..., [E_2],e_t,[E_3],...,x_n]$,其中 $e_h$ 为实体首部,$e_t$ 为实体尾部,$E_0,...,E_3$ 为实体位置。
然后讲模板嵌入到模型中 $Emb(T(x)) = \{Emb(x_0), \ldots, h_0, Emb(e_h), h_1, \ldots, h_2, Emb(e_t), h_3, \ldots, Emb(x_n)$ ,其中 $Emb()$ 为 Embedding 函数、$h_i$ 是可学习向量。
接着,Embeddings 被输入进 Encoder 中,得到句子的 hidden representation $m=Enc(Emb(T(x)))$ ,其中 $Enc()$ 为 Encoder 的隐含层,而 $m$ 是 MASK 的 hidden representation.
Contrastive Learning
我们设计了一种新的基于边界的对比学习方法,以获得判别性表示并关注困难样本,从而缓解过拟合。值得注意的是,通过这种方法,模型不需要在传统提示工程中的语言模块,从而节省了提示工程所需的劳动,并使方法更加通用。与之前工作中的线性分类器不同,我们的方法基于无参数的度量方法进行关系预测,更适合增量分类问题。
Memory Augmentation
在当前任务训练后,我们首先选择当前训练数据的典型样本存储在记忆中,然后设计精细的提示来引导ChatGPT生成多样化的样本以增强记忆。
代表性记忆采样:我们使用 K-means 算法将特征{z_i}|R_k|i=0聚类为L个簇。然后,对于每个簇,选择最接近质心的样本作为典型样本存储在记忆Mˆ中。
提示数据增强:为了利用LLMs的丰富知识,我们设计了精细的提示来激发LLMs强大的语言生成能力以生成相关示例。我们选择GPT-3.5作为生成模型。以下是提示 ChatGPT 生成具有“founded by”关系样本的示例:

Experiments