Link
Accepted ACL 2021。
Intro
小样本关系抽取(FSRE)大致可以分为两类:
- 仅使用纯文本数据,不包含外部信息。如:Siamese、Prototypical、BERT-PAIR
- 引入外部信息,以补偿 FSRE 的信息不足,如:TD-Proto
虽然引入文本描述的知识可以为 FSRE 提供外部信息并实现最先进的性能,但 TD-Proto 仅为每个实体引入一个 Wikidata 中的文本描述。然而,这可能会因为实体和文本描述之间的不匹配而导致性能下降。此外,由于每个实体的文本描述通常较长,提取长文本描述中最有用的信息并不容易。
与长文本描述相比,概念是对实体的直观和简洁的描述,可以从概念数据库(如 YAGO3、ConceptNet 和 Concept Graph 等)中轻松获得。此外,概念比每个实体的具体文本描述更抽象,这是对 FSRE 场景中有限信息的理想补充。

为了应对上述挑战,我们提出了一种新的实体概念增强的少样本关系抽取方案(CONCEPT-enhanced FEw-shot Relation Extraction,ConceptFERE),该方案引入实体概念以提供有效的关系预测线索。首先,如上表所示,一个实体可能有多个来自不同方面或层次的概念,只有一个概念可能对最终的关系分类有价值。因此,我们设计了一个概念-句子注意力模块,通过比较句子和每个概念的语义相似性来选择最合适的概念。其次,由于句子嵌入和预训练的概念嵌入不是在同一语义空间中学习的,我们采用自注意力机制对句子和选定概念进行词级语义融合,以进行最终的关系分类。
Model
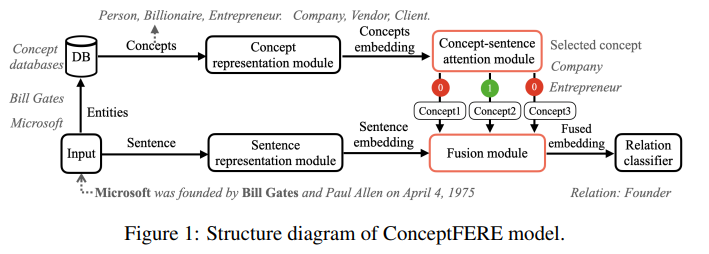
下图为 ConceptFERE 的结构。
System Overview
Sentence Representation Module 使用 BERT 作为 Encoder 来获取 Sentence Embedding,Concept Representation Module 使用 skip-grim 在 Wikipedia 文本和概念图上学习概念的表示,得到 Concept Embedding 。Relation Classifier 采用全连接层实现。
Concept-Sentence Attention Module
直观上,需要更多关注与句子语义相关度高的概念,这些概念可以为关系抽取提供更有效的线索。
首先,由于预训练的 Sentence Embedding $v_s$ 和 Concept Embedding $v_c$ 不是在同一语义空间中学习的,因此不能直接比较语义相似度。所以通过将 $v_c$ 和 $v_s$ 乘以投影矩阵 $P$ 来进行语义转换,以在同一语义空间中获得它们的表示 $v_cP$ 和 $v_sP$ ,其中 $P$ 可以通过全连接网络学习。其次,通过计算句子和每个实体概念之间的语义相似度,得到 $v_c$ 和 $v_s$ 的点积作为相似度 $sim_{cs}$ 。最后,为了从计算的相似度值中选择合适的概念,我们设计了 01-GATE 。相似度值通过 Softmax 函数归一化。如果 $sim_{cs}$ 小于设定的阈值 $α$,01-GATE 将为相应概念的注意力分数分配 0,该概念将在后续的关系分类中被排除。我们选择注意力分数为 1 的合适概念,作为参与关系预测的有效线索。
Self-Attention based Fusion Module
将句子中所有单词的嵌入和选择的概念嵌入连接起来,然后输入自注意力模块。
$$ fusion_{v_i}=\sum^N_{j=1}sim(q_i, k_j)v_j $$其中,$fusion_{v_i}$ 表示 $v_i$ 在进行单词级语义融合后的嵌入。$q_i$、$k_j$ 和 $v_j$ 来自自注意力,它们分别表示概念嵌入或单词嵌入。
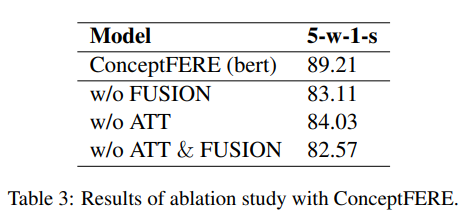
Experiment
在 Wikipedia 数据集上的实验,其中 ConceptFERE(Simple) 去掉了部分模块。
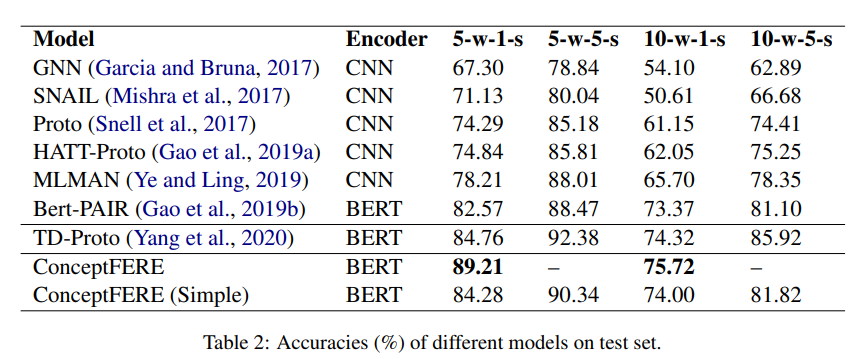
下面是消融实验: