
Link
Accepted NAACL 2024.
Intro
关系分类(Relation Classification, RC)是关系抽取中的一个重要子任务,主要关注在给定文本上下文中识别实体对之间的关系类型。为了实现这一目标,RC 模型必须从句子中提取丰富的信息,包括上下文线索、实体属性和关系特征。虽然语言模型在提取文本表示方面重要,但它们在句子表示中的向量空间使用并不理想。为了改进这一点,最近的研究通过各种技术增强了句子表示。
关系抽取在许多关系类型上面临数据有限的挑战,并且数据获取成本不成比例。为了解决这一挑战,通过小样本 RC 训练模型以快速适应新关系类型,仅使用少量标记示例。
由于区分各种关系类型的内在复杂性,RC 应用通常将实体标记令牌的表示作为句子表示。最近的工作在少样本 RC 中使用对比学习以获得更具辨别力的表示。此外,研究表明,通过提示使用 [MASK] 令牌表示句子可以改善句子表示。
本文贡献如下:
- 新方法:我们引入了一种使用对比学习对齐多重表示的方法,用于小样本关系分类。
- 适应性:我们的方法能够适应各种资源限制,并扩展到包括关系描述在内的额外信息源。
- 资源效率:我们强调了该方法的资源效率,提升了在低资源环境下的性能。
实体标记:
- 实体标记技术通过在输入句子中添加标记来指示文本中的实体。例如,句子“他在2006年世界杯上为墨西哥效力”可以被标记为“他在[E1S]2006年世界杯[E1E]上为[E2S]墨西哥[E2E]效力”。
- 在 BERT 编码器中,句子的表示是通过连接实体开始标记的表示来构建的。这种方法增强了模型对实体及其关系的理解。
- 这种技术有助于模型更好地捕捉句子中的上下文线索、实体属性和关系特征,从而提高关系分类的准确性。
对比学习:
- 对比学习是一种用于增强模型表示能力的方法,特别是在少样本关系分类任务中。
- 对比学习的主要目标是使相似的样本在表示空间中更接近,而使不相似的样本更远离。
- 在训练过程中,对比学习会创建正样本对(相似样本)和负样本对(不相似样本),并通过优化模型使正样本对的表示更接近,负样本对的表示更远。而表现在损失函数中,对比学习的损失函数旨在最大化同一输入句子不同表示之间的相似性,同时最小化不同输入句子表示之间的相似性。
- 在少样本关系分类中,对比学习通过对齐多个句子表示(如[CLS]标记、[MASK]标记和实体标记)来提取补充的判别信息,从而提高模型在低资源环境中的表现。
Approach
方法一览:
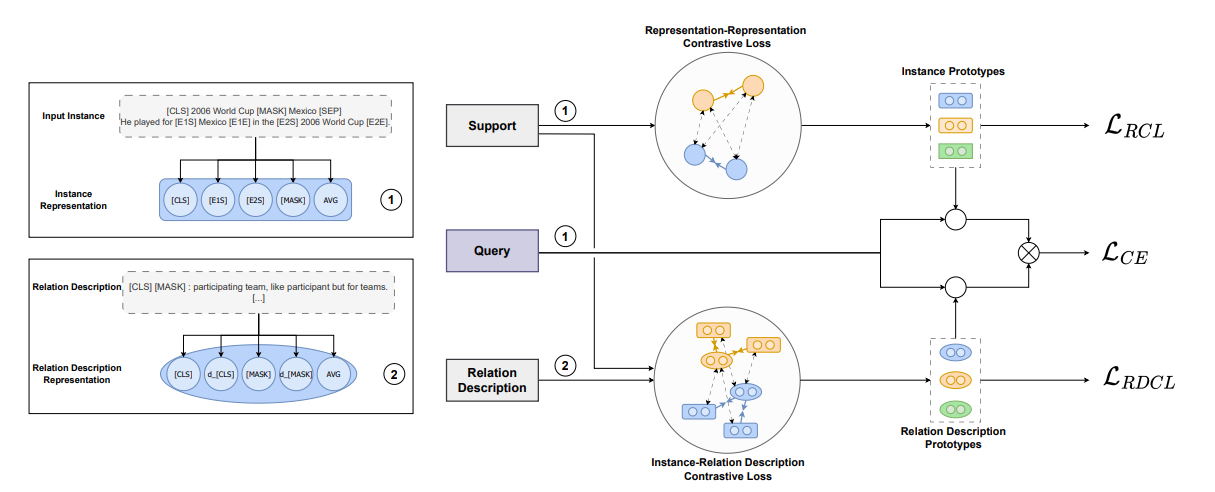
Sentence Representations
使用了平均池化从BERT编码器生成各种句子表示。
- 通过平均 token 表示来计算句子表示。同时,BERT-Base 编码器预训练期间使用 [CLS] 标记作为句子表示,捕捉整个输入序列的信息。实体标记技术通过在文本中标记实体来增强输入句子。这将输入增强为 $x = [x_0, …, [E1S], x_i, [E1E], …, x_n]$ 。句子表示通过连接实体开始标记表示 [E1S] 和 [E2S] 构建。
- 在 Prompt 方法中,RC 任务被重新表述为掩码语言建模问题。使用模板 T,每个输入被转换为包含至少一个 [MASK] 标记的 $x_{prompt} = T(x)$ 。这个掩码标记表示关系标签,并从上下文中预测,例如 $\hat x = [MASK]: x$ 。
- 使用 dropout 掩码生成增强句子表示的方法。由于实体标记表示不适用于关系描述,我们使用提示和[CLS]表示,并使用不同的dropout掩码。
Prompt-Mask Method
在 Prompt 方法中,关系分类(RC)任务被重新表述为掩码语言建模问题。这意味着将关系分类任务转换为一种填空题的形式,通过掩码语言模型来预测关系标签。具体步骤如下:
- 模板转换:每个输入句子会被转换成一个包含至少一个
[MASK]标记的模板。例如,原始句子可能是“他在2006年世界杯上为墨西哥队效力”,转换后的模板可能是“[MASK]:他在2006年世界杯上为墨西哥队效力”。- 掩码标记:在转换后的模板中,
[MASK]标记代表需要预测的关系标签。模型会根据上下文信息来预测这个掩码标记的内容。- 关系预测:通过上下文信息,模型会预测出
[MASK]标记应该填入的关系标签,例如“参与者”或“队员”。
Contrastive Representation Learning
我们的表示-表示对比损失项 (Representation-Representation Contrastive Loss) 的目标是对齐个体表示,以提取关系分类任务的判别信息。
我们从每个输入句子中提取 $M$ 个不同的表示,并将这些表示视为正实例对。因此,训练集中其他句子的表示作为负实例对。对于给定的 $r_i^m$ ($m \in M, \ i \in N \times K$) 我们定义正实例 $r^+_i $ 和负实例 $ r^-_i$ 如下:
$$ r_i^+=\{ r_i^{k \ne m} \ | \ k \in M \} \\ r_i^-=\{ r_{j \ne i}^m \ | \ j \in N \times K \} $$

Relation Classification
我们通过对支持集中 K 个实例表示取平均值来获得 N 个类原型。我们使用向量点积计算查询实例与支持原型之间的相似度,并选择最相似的类原型。
对于关系描述,我们计算查询实例与关系描述表示 D 之间的相似度。我们将从关系描述中获得的相似度与从类原型中获得的相似度相加,并选择最相似的原型和关系描述。我们计算交叉熵损失 $LCE = −log (z_y)$,其中 $z_y$ 是类 $y$ 的概率。总损失定义为各个损失项的总和 $L = L_{CE} + L_{RCL} + L_{RDCL}$ 。
Experiments
实验结果:
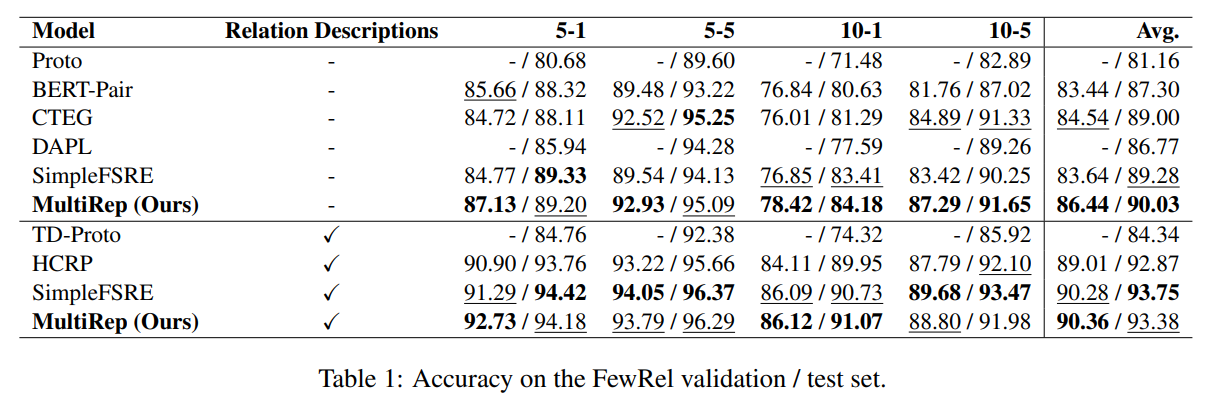
消融实验:
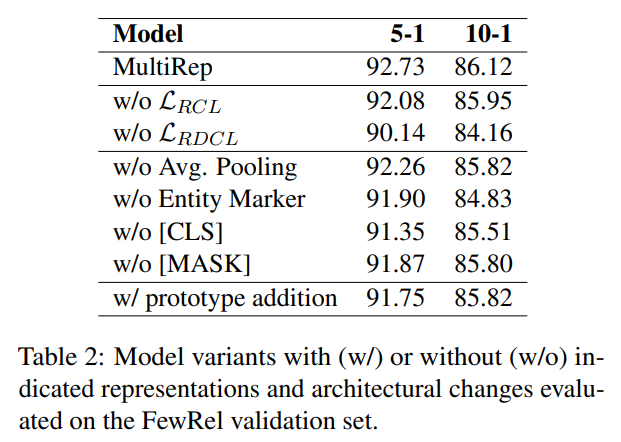
对于 N-way K-shot ,增大 N 对模型的影响:
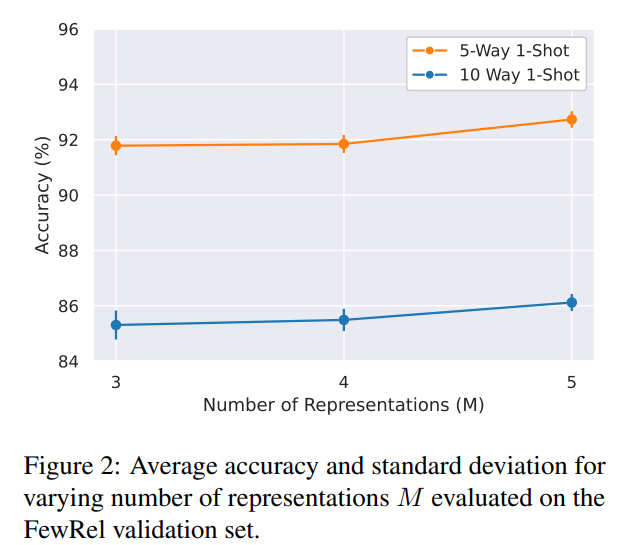
N-way K-shot 评估是一种用于评估机器学习模型在少样本学习(few-shot learning)任务中的性能的方法。具体来说:
- N-way:表示模型需要在N个不同的类别中进行分类。例如,如果N=5,那么模型需要在5个类别中进行分类。
- K-shot:表示每个类别中有K个样本用于训练模型。例如,如果K=1,那么每个类别只有一个样本用于训练。