Link
Accepted by ACL 2024.
Intro
联合抽取旨在使用单一模型检测实体及其关系,这是自动知识库构建中的关键步骤。为了廉价地获取大量标注的联合训练数据,提出了远程监督(Distantly Supervise,DS),通过将知识库(Knowledge Base,KB)与未标注的语料库对齐,自动生成训练数据。假设如果一个实体对在 KB 中有关系,则包含该对的所有句子都表达相应的关系。
然而,DS 带来了大量的噪声标签,显著降低了联合抽取模型的性能。此外,由于开放域 KB 中实体的模糊性和覆盖范围有限,DS 还会生成噪声和不完整的实体标签。在某些情况下,DS 可能导致 KB 中包含超过30%的噪声实例,使得学习有用特征变得不可能。
处理这些噪声标签的先前研究要么考虑弱标注的实体,即远程监督的命名实体识别(NER),要么考虑噪声关系标签,即远程监督的关系抽取(RE),它们专注于设计新颖的手工制作关系特征、神经架构和标注方案以提高关系抽取性能。此外,使用大型语言模型(LLMs)的上下文学习(ICL)也很流行。然而,它们资源需求高,对提示设计敏感,可能在处理复杂任务时表现不佳。
为了廉价地减轻两种噪声源,我们提出了 DENRL (Distantly-supervised joint Extraction with Noise-Robust Learning)。DENRL 假设
- 可靠的关系标签,其关系模式显著表明实体对之间的关系,应该由模型解释;
- 可靠的关系标签也隐含地表明相应实体对的可靠实体标签。
具体来说,DENRL应用词袋正则化(BR)引导模型关注解释正确关系标签的显著关系模式,并使用基于本体的逻辑融合(OLF)通过概率软逻辑(PSL)教授底层实体关系依赖性。这两种信息源被整合形成噪声鲁棒损失,正则化标注模型从具有正确实体和关系标签的实例中学习。接下来,如果学习到的模型能够清晰地定位关系模式并理解候选实例的实体关系逻辑,它们将被选择用于后续的自适应学习。我们进一步采样包含已识别模式中对应头实体或尾实体的负实例以减少实体噪声。我们迭代学习一个可解释的模型并选择高质量实例。这两个步骤相互强化——更可解释的模型有助于选择更高质量的子集,反之亦然。
Joint Extraction Architecture
Tagging Scheme

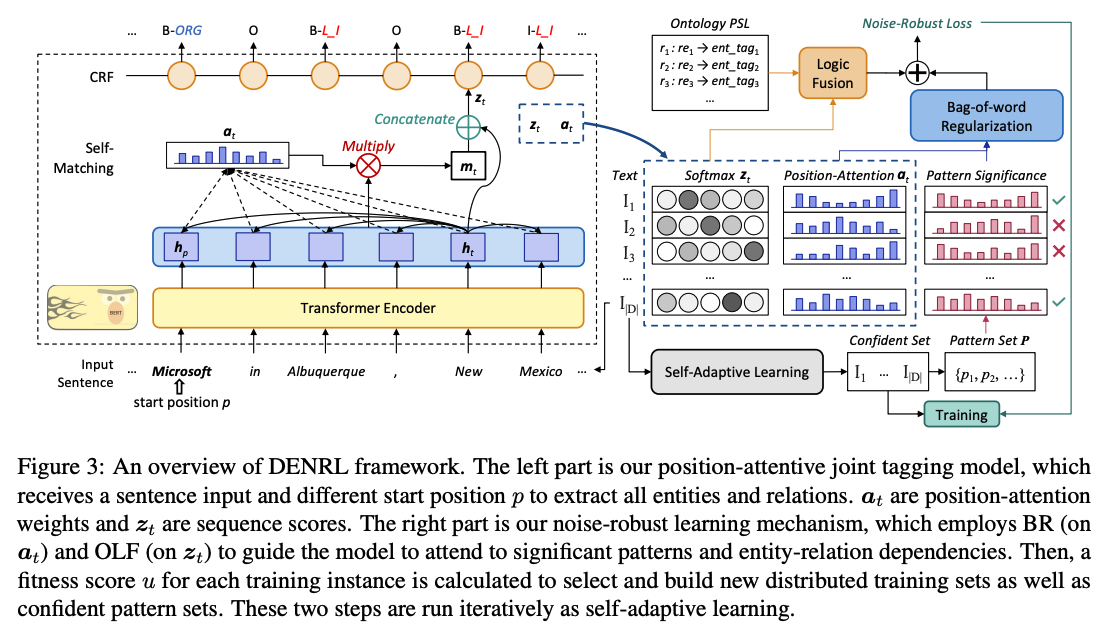
为了同时抽取实体(提及和类型)和关系,我们为每个起始位置 $p$ 标注四元组 ${e_1, tag_1, e_2, r_e}$,并定义 “BIO” 标记来编码位置。对于一个 $T$ 个 token 的句子,我们根据不同的起始位置标注 $T$ 个不同的标记序列。
对于每个标记序列,如果 $p$ 是一个实体的起始位置(该序列是一个实例),则在 $p$ 处标注实体类型,并用关系类型标注与 $p$ 处实体有关系的其他实体。其余的令牌标注为 “O”(Outside),表示它们不对应头实体。这样,每个标记序列将生成一个关系四元组。
我们将包含至少一个关系的实例定义为正实例,没有关系的实例定义为负实例。“BIO”(Begin, Inside, Outside)标记用于指示每个实体中令牌的位置信息,以便同时提取多词实体和关系类型。注意,我们不需要尾实体类型,因为每个实体都会被查询,我们可以从 T 标记序列中获得所有实体类型及其关系。
Tagging Model
Self-Match BERT
CRF
Noise-Robust Learning
Bag-of-word Regularizition(BR)
最初作为一种模式关注损失提出,注意力正则化已被证明对减少关系噪声有效,但它只考虑单一关系模式的注意力,忽略了模型的位置感知,因此无法识别重叠关系。我们通过引入词袋频率作为指导来学习信息丰富的关系。对于输入句子 $S$,$S$ 中的实体对$(e_1, e_2)$、关系标签 $r_e$ 和解释 $e_1$ 与 $e_2$ 关系的关系模式 $p$ ,我们定义词袋频率(即模式显著性)为条件模式 $p$ 的相应指导分数 $\alpha_p$。以关系 “包含” 为例,其词袋是一组出现在相应模式集中的词{“capital of”, “section in”, “areas of”, …}。指导模型探索新的高质量模式 $p$,例如“section of”,“areas in”等。
Ontology-Based Logic Fusion(OLF)
概率软逻辑(Probabilistic Soft Logic, PSL)使用[0, 1]区间内的软真值表示谓词,这表示我们的标记分类概率 $p(y_t|w_t)$ 为一个凸优化问题。我们根据数据本体使用人工注释适应 PSL 到实体关系依赖规则,例如关系类型Founder_of 应当包含(头)实体类型 PERSON。违反这些规则的训练实例将被惩罚以增强对实体关系一致性的理解。
Self-Adaptive Learning(SAL)
自适应学习旨在迭代选择具有信息性关系模式和实体标签的高质量实例。在每个训练周期中,选择更多精确标注的实例来指导模型关注信息性证据进行联合抽取。对于实例选择,需要更多多样化的模式来选择干净的标签并发现更多可信的关系模式。根据注意力机制和实体关系逻辑,训练的标注器可以判断每个词在识别实体对及其关系中的重要性,并预测合理的实体关系标签对。
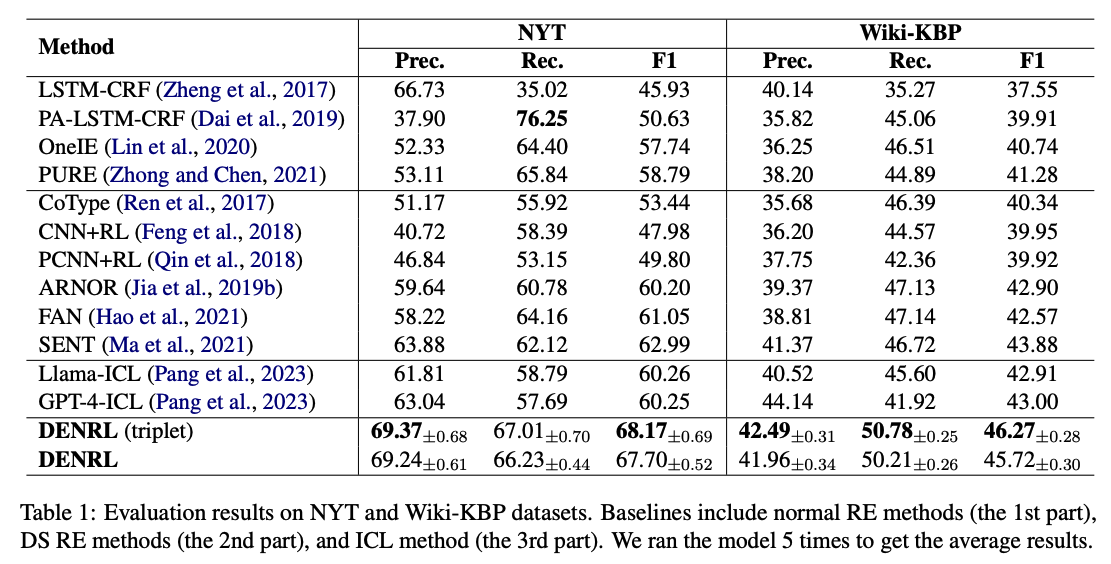
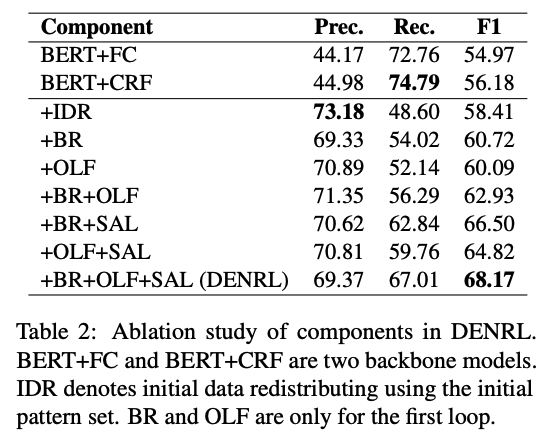
Experiments