Link
[2210.13733] Better Few-Shot Relation Extraction with Label Prompt Dropout (arxiv.org)
Accepted EMNLP 2022.
Intro
在这项工作中,我们提出了一种称为标签提示丢弃(Label Prompt Dropout, LPD)的新方法。我们直接将文本标签和上下文句子连接在一起,并将它们一起输入到 Transformer Encoder 中。文本标签作为标签提示,通过自注意力机制引导和规范 Transformer Encoder 输出标签感知的关系表示。在训练过程中,我们随机丢弃提示标记,使模型必须学会在有和没有关系描述的情况下工作。实验表明,我们的方法在两个标准的FSRE数据集上取得了显著的改进。我们进行了广泛的消融研究,以证明我们方法的有效性。此外,我们强调了先前研究工作评估设置中的一个潜在问题,即预训练数据中包含的关系类型实际上与测试集中的关系类型重叠。我们认为这对于少样本学习来说可能不是一个理想的设置,并表明现有工作的性能提升可能部分归因于这种“知识泄漏”问题。我们建议过滤掉预训练数据中所有重叠的关系类型,并进行更严格的少样本评估。总之,我们做出了以下贡献:
- 我们提出了 LPD,一种新的标签提示丢弃方法,使 FSRE 中的文本标签得到了更好的利用。这种简单的设计显著优于以前使用复杂网络结构将文本标签和上下文句子融合的方法。
- 我们识别了文献中先前实验设置的局限性,并提出了一个更严格的FSRE评估设置。对于这两种设置,我们都显示出比以前的最先进方法更强的改进。
Related Work
Few-Shot Relation Extraction
Prompt-Based Fine-Tuning
基于提示的模型在小样本和零样本学习中表现出色。这一研究方向的模型尝试将下游微调任务与预训练的掩码语言建模目标对齐,以更好地利用预训练语言模型的潜在知识。
然而,与许多其他自然语言处理任务(如二元情感分析中的“正面/负面”)的标签语义直观不同,关系抽取中的关系类型可能非常复杂,通常需要较长的句子来描述。例如,FewRel 中的关系 P2094 被描述为“由监管机构进行的官方分类,主体(事件、团队、参与者或设备)符合纳入标准”。基于提示的模型在这种情况下会遇到困难,因为它们需要固定的模板(例如,提示模板中的 [MASK] 令牌数量必须固定)。以前的方法不得不依赖手动设计的提示模板,并使用关系名称而不是关系描述。
为了解决这个问题,我们提出直接使用整个关系描述作为提示,而不使用任何掩码令牌。在传统的基于提示的模型中,提示用于创建自然描述,以便模型可以在 [MASK] 位置进行更好的预测,而本研究中使用的标签提示通过自然描述来帮助规范模型输出更好的类别表示。
Approach
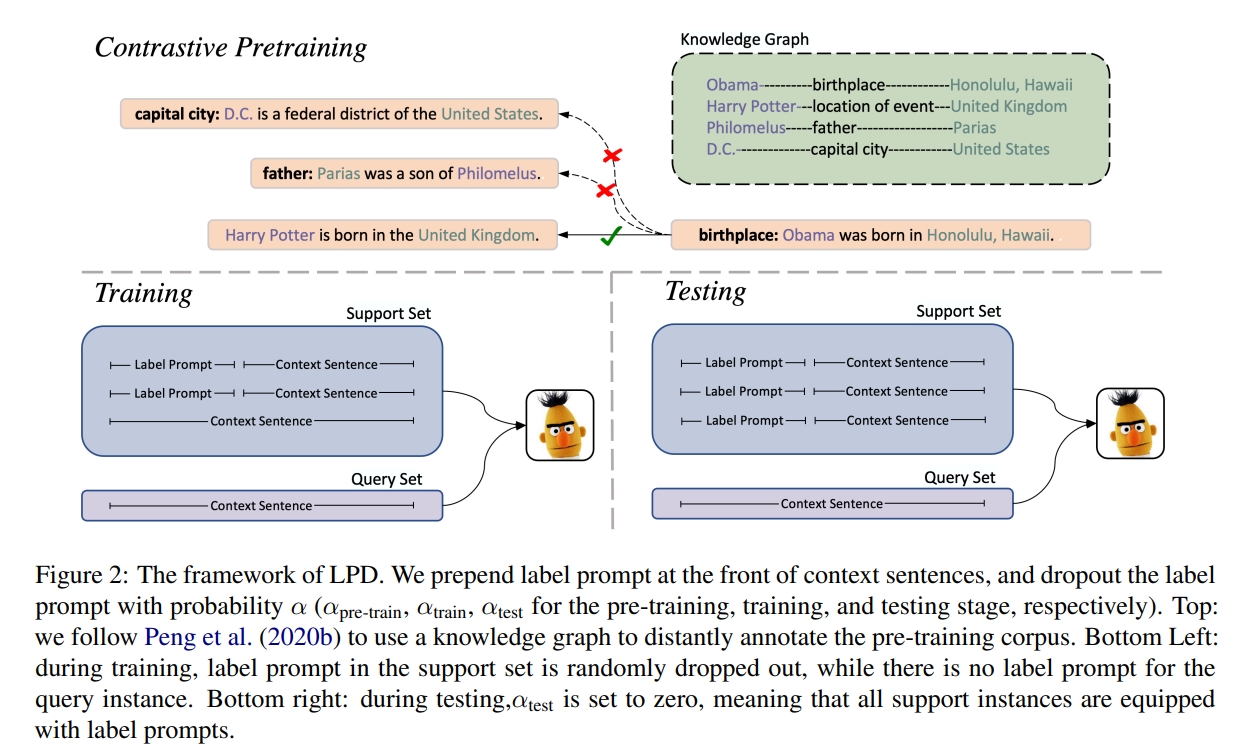
Training with Label Prompt Dropout
对于每个支持实例,我们直接将关系描述和上下文句子用“:”连接起来。例如,句子“北京举办了2022年冬季奥运会”将变成“事件地点: 北京举办了2022年冬季奥运会。” 这个想法是创建一个自然的实例,其中定义首先给出,然后是例子。关系描述和冒号作为标签提示,引导 Transformer Encoder 输出一个标签感知的关系表示。为了防止模型完全依赖标签提示而忽略上下文句子,标签提示会以 $α_{train}$ 的概率随机丢弃。例如,上图中的支持实例“十进制数最早在印度发展起来”保持其初始形式,因为其标签提示被丢弃了。对于查询实例,我们直接输入句子而不带任何标签提示。这是因为查询集本质上与测试集相同,我们不应假设可以访问真实知识。随后,使用特殊实体标记来标记头部和尾部,并在句子的前后添加特殊的分类和分隔标记,例如“[CLS] 事件地点: [E1] 北京 [/E1] 举办了 [E2] 2022年冬季奥运会 [/E2]。” 解析后的句子然后被送入Transformer Encoder。
实体标记 + 句子标记 + Prompt 拼接/标记,目前看到的 Few-Shot Learning 的无脑三板斧。
Testing with Prompt Guided Prototypes
类似于标准的 dropout 操作,在训练期间随机丢弃神经元,并在测试期间恢复,LPD 在测试期间也不会丢弃任何支持实例的标签提示。通过将关系描述与每个支持实例一起输入,我们实际上为每个支持类获得了一个提示引导的原型。
Contrastive Pre-training with Label Prompt Dropout
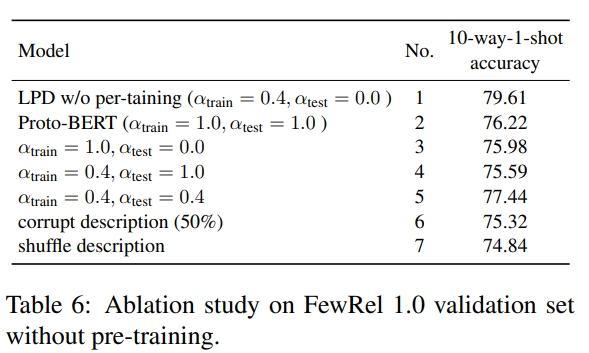
LPD 也可以添加到关系抽取的领域特定预训练阶段。实际上,预训练是 LPD 的一个关键步骤,因为预训练阶段的大规模数据允许模型适应 LPD 的输入格式,并学习如何从标签提示中提取有用信息。我们用了一个对比学习框架,采样用于对比预训练的正负对。给定一个知识图谱 $K$ 和两个包含实体对 $(h1, t1)$ 和 $(h2, t2)$ 的句子,如果 $K$ 定义了一个关系 $R$ ,使得 $(h1, t1)$ 和 $(h2, t2)$ 属于该关系,则这两个句子将被标记为正对。如果句子不构成正对,则将其采样为负对。例如,在图1中,实体对(Harry Potter, United Kingdom)和(Obama, Honolulu Hawaii)在 KG 中形成相同的“出生地”关系。因此,包含这两个实体对的句子被采样为正对。根据这种方法,数据被噪声标记,因为在 KG 中形成关系的两个实体在句子中可能并不表达这种关系。例如,“D.C.是美国的一个联邦区”将被标记为“首都”的一个实例,即使这种关系在句子中没有表达出来。我们随机用特殊的 [BLANK] 标记掩盖实体跨度,概率为 $ ρ_{blank} = 0.7$ ,以避免依赖实体提及的浅层线索。
Results