
基于预训练模型的部分标签命名实体识别模型
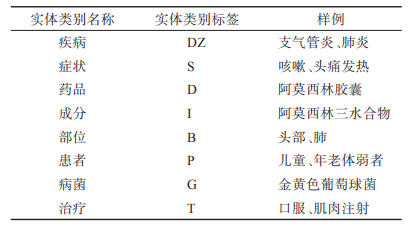
对于输入的药品说明书文本先利用少量样本微调的预训练模型进行实体抽取,如上图所示,“云南白药成分:三七、麝香、草乌等”通过预训练模型识别出 “麝香”和“草乌”两个“成分”类型的实体。由于受标注样本数量限制,预训练模型经少量样本微调后,其召回率不高,如例子中“云南白药”“三七”两个实体未能识别,但把预训练模型识别出的部分实体及该实体的类型标签作为一种提示信息输入到后面的部分标签模型,这将有助于部分标签模型进行实体抽取任务。
部分标签模型采用平面格结构对输入文本及预训练语言模型识别的部分实体进行整合,整合信息包括字符或实体词 token、标签 tag、头部位置标记 head 和尾部位置标记 tail。部分标签模型使用 Transformer 建模平面格结构的编码输入,通过 Transformer 的自注意力机制使字符可以与潜在实体词直接交互。最后将 Transformer 提取特征表示,输入到 CRF层预测实体标签。
训练策略
对整体模型训练分两阶段:
- 利用少量完全标注的语料对预训练模型进行微调,再对这些完全标注语料采用标注样本实体掩盖(mask)策略进行样本数据增广,使用增广后的样本数据集对部分标签模型进行训练;
- 预训练模型和部分标签模型进行联合训练。
对比实验
尽管 BERT- BILSTMCRF 模型在医疗、政务等领域的命名实体识别得到广泛应用 ,但由于采用 LSTM 神经网络提取字符特征,其效果明显低于 FLAT 和本文模型,而 FLAT、 MECT4CNER 以及本文模型都采用 Transformer 网络提取特征。
MECT4CNER 是在 FLAT 的基础上结合汉字结构信息与词典信息设计的模型,但本次实验表明 MECT4CNER 应用于药品说明书命名实体识别时, 汉字结构信息未能对提高模型性能带来更多增益, 反而降低了召回率,使得 F1 值比 FLAT 模型更低。 本文模型对 FLAT 模型所提出的平面格结构进行了扩展,增加的标签信息能对提升模型性能带来增益, 从而 F1值取得了较优的效果。
FLAT模型是为中文命名实体识别设计的,它将复杂的字词格结构转换为平坦的结构。每个跨度对应于原始格中的一个字符或潜在词及其位置。FLAT利用Transformer的强大功能和精心设计的位置编码,能够充分利用格信息,并具有出色的并行能力。实验表明,FLAT在性能和效率上都优于其他基于词典的模型。
MECT4CNER模型结合了字词格和部首流,不仅具有FLAT的词边界和语义学习能力,还增加了汉字部首的结构信息。通过融合汉字的结构特征,MECT能够更好地捕捉汉字的语义信息,从而提高中文NER的性能。