
中文NER的难点
- 词边界模糊。中文没有像英文等语言一样使用空格或其他分隔符来表示词边界,这种特点导致中文命名实体识别面临着边界歧义和识别困难的问题。例如,“计算机科学与技术系”中“计算机科学与技术”是一个 复合词,边界不明确。
- 语义多样化。中文存在大量多义词,一个词汇可能会被用于不同的上下文中表示不同的含义。
- 形态特征模糊。在英语中,一些指定类型的实体的第一个字母通常是大写的,例如指定人员或地点的名称。这种信息是识别一些命名实体的位置和边界的明确特征。在中文命名实体识别中缺乏汉语形态的显式特征,增加了识别的难度。
- 中文语料库内容较少。命名实体识别需要大量 的标注数据来训练模型,但中文标注数据数量及质量有限,导致命名实体识别模型的训练更为困难。
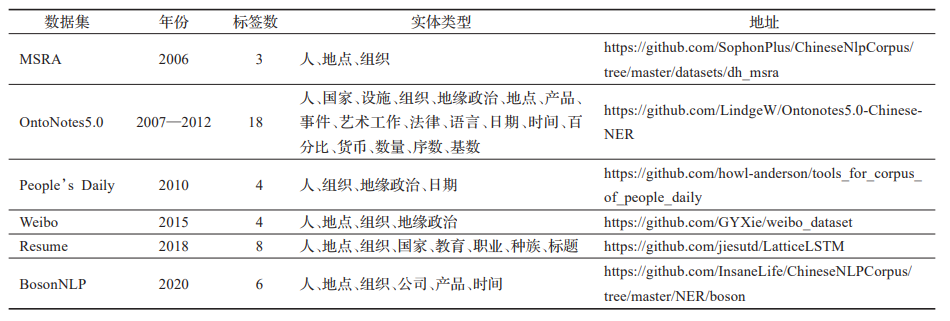
CNER数据集
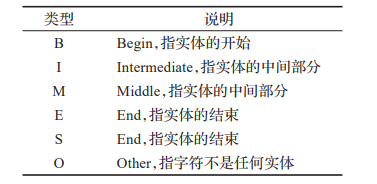
CNER标注方式、性能指标
BIO标注、 BMES标注以及BIOSE标注方案。
性能指标和NER一样,Precision、Recall、Accuracy、F1-score 是常用指标。
近几年的CNER模型构成
嵌入层
基于字符的模型
基于字符的模型将单词表示为字符序列的方法,它通过输入文本的字符级别表示,不需要明确的词边界信息,可以更好地处理CNER中的边界模糊问题。为解决相邻字符之间强联系的问题,Zhang 等人[40] 提出一种新的动态嵌入方法,该方法使用注意力机制来 组合嵌入层中的字符和单词向量特征。基于字符的模型存在不能携带语义信息、难以处理歧义词的缺点[42] 。
基于词的模型
基于词的模型是将中文数据集的文本以词语的形 式作为输入,借助分词系统[43] 对数据集进行分词。基于词的模型可以捕捉到词与词之间的语义关系,在处理一些长词汇的实体时具有良好的效果。基于词的模型存在分词错误和在处理不规则的词以及新词时比较困难的缺点。Ma等人[45] 使用双向 LSTM、CNN 和 CRF 的组合,提出一种 中性网络结构,自动从单词和字符级别的表示中获益, 实现了端到端的 NER。
混合模型
混合模型是将基于字符的模型和基于词的模型结合起来,由于基于字符的模型存在字与字之间语义提取缺失问题,基于词的模型存在分词错误的问题,同时将字符和词作为嵌入表示可以使模型具有较好的鲁棒性和识别精度。
基于 Transformer 的双向编码(bidirectional encoder representations from Transformer,BERT) 模型[51] 是中文命名实体识别中最常用的预训练模型, BERT模型可以考虑整个输入句子的上下文信息,有助于提高模型对命名实体的理解和识别准确性。对于给定的字符,BERT将其字符位置嵌入、句子位置嵌入和字符嵌入作为输入连接起来,然后使用掩码语言模型[52] 对输入句子进行深度双向表示预训练,以获得强大的上下文字符嵌入。
编码层
编码层主要是将嵌入层输入的文本转换成一个高 维的特征向量,方便后续的分类器对文本进行分类。
卷积神经网络
CNN最初是为计算 机视觉研究开发的,但它已被证明可以有效地捕获具有卷积运算的 n-gram 的信息语义特征[61] 。
循环神经网络
Quyang 等人[67] 提出一种用于 CNER 的深度学习模型,该模型采用双向 RNN-CRF 架构,使用连接的 n -gram 字符表示来捕获丰富的上下文信息。Dong 等人[37] 将双向 LSTM-CRF 神经网络用于 CNER,该网络同时利用字符级和部首级表示,是第一个研究 BiLSTM-CRF 架构中的中文部首级表示,并且在没有精心设计的功能的情况下获得更好的性能。
Transformer
Transformer是一种深度神经网络模型,由谷歌团队在 2017 年提出的神经网络模型[68] ,它只基于注意力机制,而不是采用循环和卷积,旨在解决序列到序列的自然语言问题,在中文命名实体识别中取得不错的性能,且将训练时间大幅度压缩。
解码层
解码层是 NER 模型最后的阶段,主要任务是将上下文表示作为输入并生成与输入序列相对应的标签序列,目前主流方法有两种:MLP+Softmax与CRF
MLP+Softmax
CRF
条件随机场(CRF)模型[75] 作为一种判别式概率模型,可以直接建模序列标注任务中标签之间的依赖关系,能够有效地解决标签之间的冲突和歧义问题。CRF 模型通常会利用已经预测出的局部标签序列,通过对全局标签序列的建模,来计算全局最优的标签序列。