Machine Translation
Machine Translation is the task of translating a sentence $x$ from one language to a sentence $y$ in another language.
Simple History:
- 1990s-2010s: Statistical Machine Translation
- After 2014: Neural Machine Translation
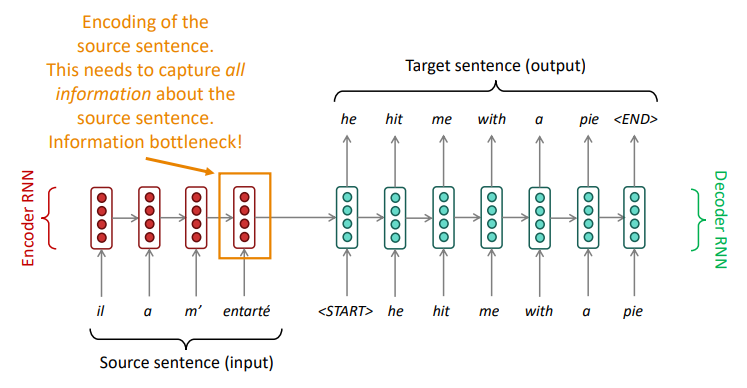
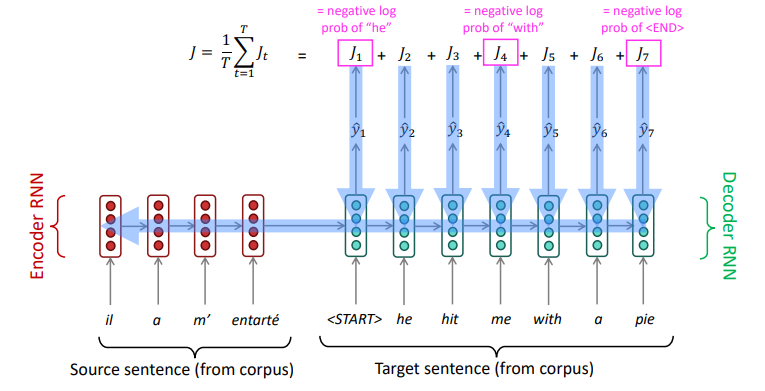
Sequence to Sequence Model
The sequence-to-sequence model is an example of a Conditional Language Model
- Language Model because the decoder is predicting the next word of the target sentence $y$
- Conditional because its predictions are also conditioned on the source sentence $x$
Multi-layer RNNs in practice
High-performing RNNs are usually multi-layer.
For example: In a 2017 paper, Britz et al. find that for Neural Machine Translation, 2 to 4 layers is best for the encoder RNN, and 4 layers is best for the decoder RNN.
Transformer-based networks (e.g., BERT) are usually deeper, like 12 or 24 layers.
Greedy decoding
We saw how to generate (or “decode”) the target sentence by taking argmax on each step of the decoder. This is greedy decoding (take most probable word on each step)
But this way has some problems. Like this:

Exhaustive search decoding
Ideally, we want to find a (length T) translation y that maximizes

We could try computing all possible sequences $y$
- This means that on each step t of the decoder, we’re tracking $V^t$ possible partial translations, where $V$ is vocab size
- This $O(V^T)$ complexity is far too expensive!
Beam search decoding
Core idea: On each step of decoder, keep track of the $k$ most probable partial translations (which we call hypotheses)
- $k$ is the beam size (in practice around 5 to 10)

Beam search is not guaranteed to find optimal solution, but much more efficient than exhaustive search.
In greedy decoding, usually we decode until the model produces an “<END>” token.
In beam search decoding, different hypotheses may produce <END> tokens on different timesteps.
We have our list of completed hypotheses.
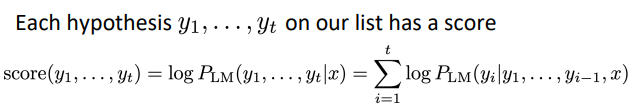
Problem with this: longer hypotheses have lower scores.
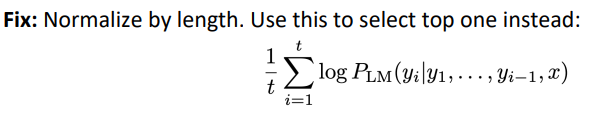
The bottleneck problem