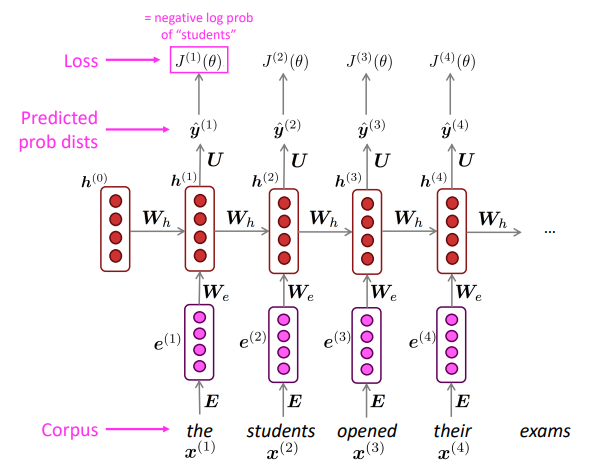
Training an RNN Language Model
- Get a big corpus of text which is a sequence of words $x^{(1)},...,x^{(T)}$
- Feed into RNN-LM; compute output distribution $\hat y ^{(t)}$ for every timestep $t$
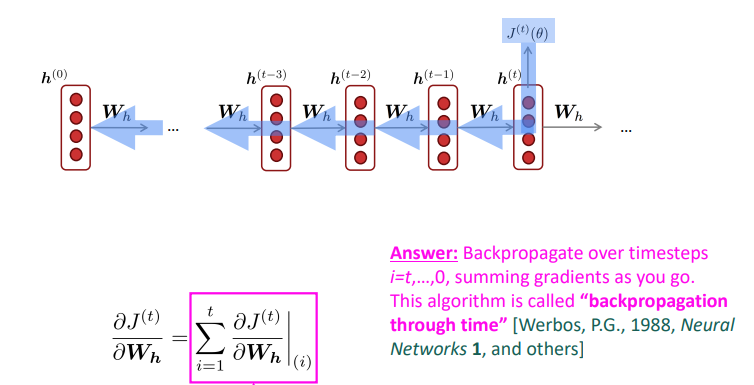
Backpropagation for RNNs
Problems with Vanishing and Exploding Gradients
Vanishing gradient intuition
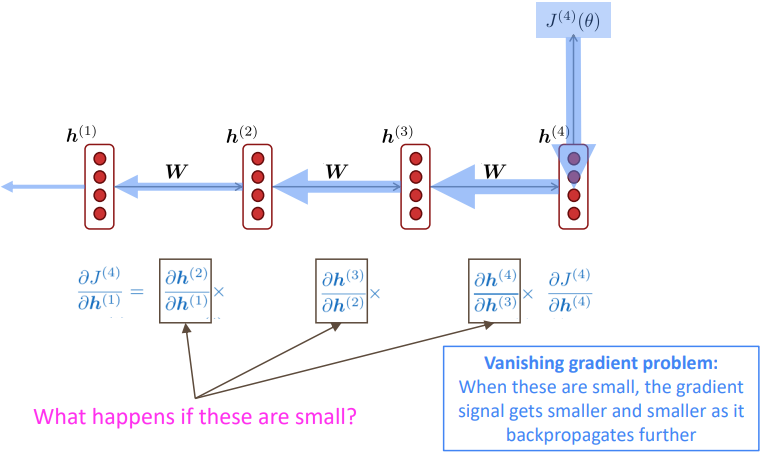
Why is vanishing gradient a problem?
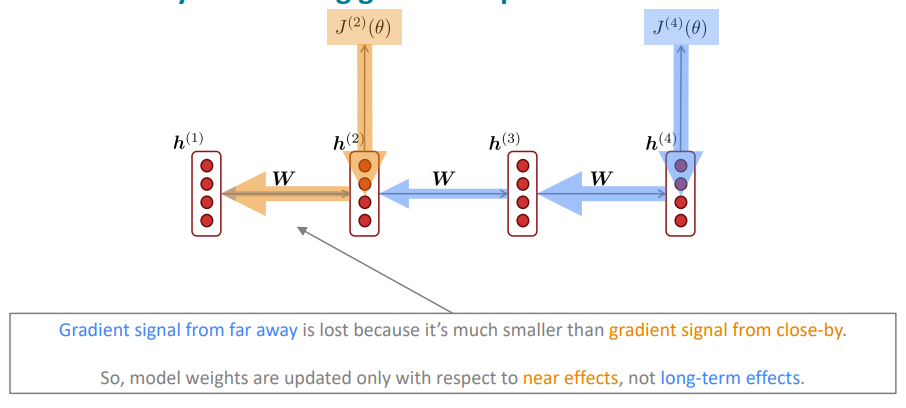
- 来自远处的梯度信号会丢失,因为它比来自近处的梯度信号小得多
- 因此,模型权重只会根据近期效应而不是长期效应进行更新
If gradient is small, the model can’t learn this dependency. So, the model is unable to predict similar long distance dependencies at test time.
Why is exploding gradient a problem?
- This can cause bad updates: we take too large a step and reach a weird and bad parameter configuration (with large loss)
- In the worst case, this will result in Inf or NaN in your network (then you have to restart training from an earlier checkpoint)
Gradient clipping: solution for exploding gradient
- Gradient clipping 梯度裁剪: if the norm of the gradient is greater than some threshold, scale it down before applying SGD update
- Intuition: take a step in the same direction, but a smaller step
Long Short-Term Memory RNNs
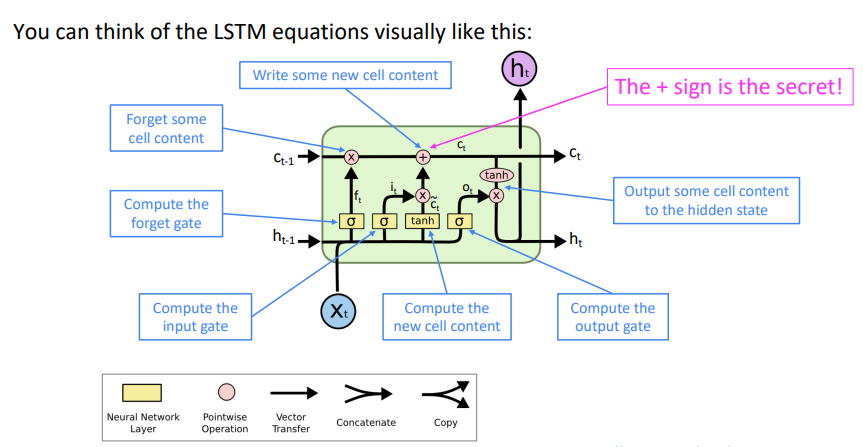
On step $t$ , there is a hidden state $h^{(t)}$ and a cell state $c^{(t)}$
- Both are vectors length $n$
- The cell stores long-term information
- The LSTM can read, erase, and write information from the cell
The selection of which information is erased/written/read is controlled by three corresponding gates
- The gates are also vectors length $n$
- On each timestep, each element of the gates can be $open (1), closed (0)$, or somewhere in-between
- The gates are dynamic: their value is computed based on the current context

- 遗忘门:控制上一个单元状态的保存与遗忘
- 输入门:控制写入单元格的新单元内容的哪些部分
- 输出门:控制单元的哪些内容输出到隐藏状态
- 新单元内容:这是要写入单元的新内容
- 单元状态:删除(“忘记”)上次单元状态中的一些内容,并写入(“输入”)一些新的单元内容
- 隐藏状态:从单元中读取(“output”)一些内容
How does LSTM solve vanishing gradients?
The LSTM architecture makes it easier for the RNN to preserve information over many timesteps.
LSTM doesn’t guarantee that there is no vanishing/exploding gradient, but it does provide an easier way for the model to learn long-distance dependencies