Word structure and subword models
We assume a fixed vocab of tens of thousands of words, built from the training set. All novel words seen at test time are mapped to a single UNK.

Finite vocabulary assumptions make even less sense in many languages. Many languages exhibit complex morphology, or word structure.
The byte-pair encoding algorithm (BPE)
Subword modeling in NLP encompasses a wide range of methods for reasoning about structure below the word level.
- The dominant modern paradigm is to learn a vocabulary of parts of words (subword tokens)
- At training and testing time, each word is split into a sequence of known subwords
Byte-pair encoding is a simple, effective strategy for defining a subword vocabulary.
- Start with a vocabulary containing only characters and an “end-of-word” symbol
- Using a corpus of text, find the most common adjacent characters “a,b”; add “ab” as a subword
- Replace instances of the character pair with the new subword; repeat until desired vocab size
字节对编码(Byte-pair encoding,简称BPE)是一种简单且有效的定义子词词汇的方法。
- 从仅包含字符和“词尾”符号的词汇表开始。
- 使用一组文本语料,找到最常见的相邻字符对,例如“a,b”;将“ab”添加为一个子词。
- 用新的子词替换字符对的实例;重复此过程,直到达到所需的词汇大小。
这种方法通过逐步合并最常见的字符对,逐渐构建出一个更紧凑和有效的子词词汇表。这在自然语言处理任务中非常有用,因为它可以减少词汇表的大小,同时保持对文本的良好表示能力。
Motivating model pretraining from word embeddings
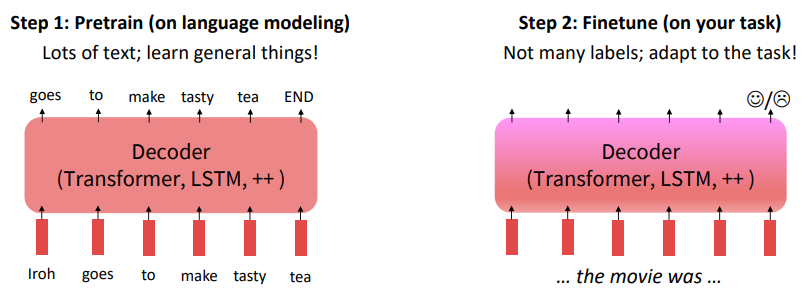
The Pretraining / Finetuning Paradigm
Pretraining can improve NLP applications by serving as parameter initialization.
Stochastic gradient descent and pretrain/finetune
Why should pretraining and finetuning help, from a “training neural nets” perspective?
Consider, provides parameters $\hat{\theta}$ by approximating $\underset{\theta}{min} \ L_{pretrain}(\theta)$ , it‘s pretraining loss
Then, finetuning approximates $\underset{\theta}{min} \ L_{finetune}(\theta)$ , starting at $\hat{\theta}$ , it’s finetuning loss
The pretraining may matter because stochastic gradient descent sticks (relatively) close to $\hat{\theta}$ during finetuning
Pretraining for three types of architectures

Pretraining decoders

Decoder-only Models: GPT, GPT2
Pretraining encoders
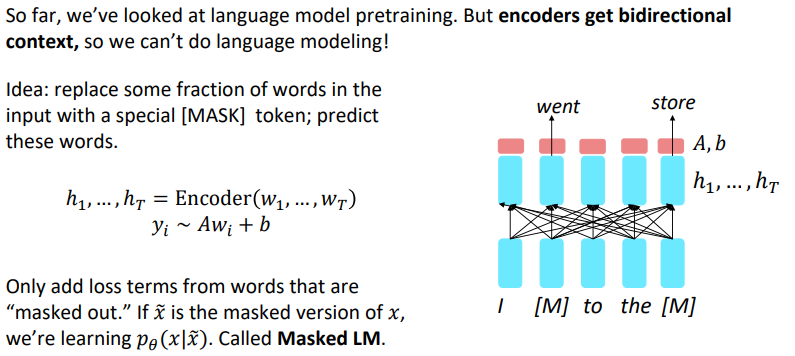
Why not used pretrained encoders for everything?
If your task involves generating sequences, consider using a pretrained decoder; BERT and other pretrained encoders don’t naturally lead to nice autoregressive (1-word-at-a-time) generation methods.
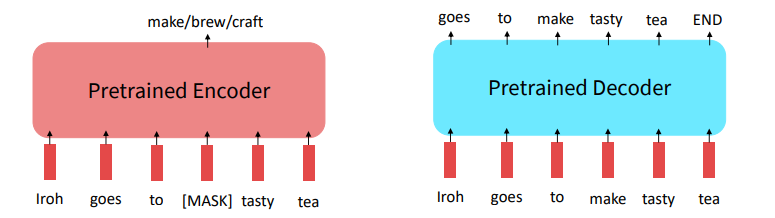
Encoder-only Models: BERT, RoBRETa, SpanBERT…
Pretraining encoder-decoders
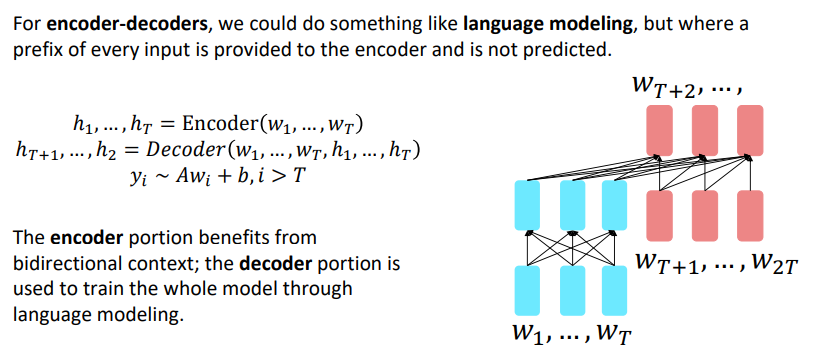
Encoder-Decoder Model: T5